怎么才叫熟悉http协议?
“熟悉http协议”,肯定很多IT小伙伴都在招聘岗位上看得到过,但是怎么才叫熟悉http协议呢?抽空梳理了一下,也算是对这一部分知识的笔记吧!
“熟悉http协议”,肯定很多IT小伙伴都在招聘岗位上看得到过,但是怎么才叫熟悉http协议呢?抽空梳理了一下,也算是对这一部分知识的笔记吧!
可能对于大部分人来说,网络web编程就是使用一些第三方库来进行请求和响应的处理,再多说一点就是这个URI要使用POST方法,对于携带的数据需要处理成为formdata。
基础知识
Q1: HTTP协议是什么?用来干什么?
HTTP协议是基于TCP/IP协议的应用层协议,主要规定了客户端和服务端之间的通信格式。主要作用也就是传输数据(HTML,图片,文件,查询结果)。
#网络分层
互联网的实现分成了几层,如何分层有不同的模型(七层,五层,四层),这里按五层模型来解释:
(靠近用户)应用层 < 传输层 < 网络层 < 链接层 < 物理层(靠近硬件)
| 层级 | 作用 | 拥有协议 |
|---|---|---|
| 物理层 | 传送电信号0 1 | 无 |
| 数据链路层 | 定义数据包;网卡MAC地址;广播的发送方式; | Ethernet 802.3; Token Ring 802.5 |
| 网络层 | 引进了IP地址,用于区分不同的计算机是否属于同一网络 | IP; ARP; RARP |
| 传输层 | 建立端口到端口的通信,实现程序时间的交流,也就是socket | TCP; UDP |
| 应用层 | 约定应用程序的数据格式 | HTTP; FTP; DNS |
每一层级,都是解决问题而诞生的,也就是他们各自作用对应的问题,推荐参考资料中的“互联网协议入门”。
#HTTP通信流程
#拓展–三次握手和四次挥手
经常在其他地方看到这些,一直不知道了解这部分有什么用,但是syn Flood攻击,恰恰是利用了TCP三次握手中的环节。利用假IP伪造SYN请求,服务端会多次尝试发送SYN-ACK给客户端,但是IP并不存在也就无法成功建立连接。在一定时间内伪造大量这种请求,会导致服务器资源耗尽无法为正常的连接服务。(注:服务器SYN连接数量有限制,SYN-ACK超时重传机制)
三次握手流程:
- The client requests a connection by sending a SYN (synchronize) message to the server.
- The server acknowledges this request by sending SYN-ACK back to the client.
- The client responds with an ACK, and the connection is established.
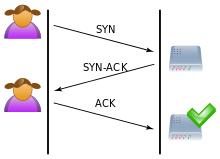
四次挥手流程:
When an endpoint wishes to stop its half of the connection, it transmits a FIN packet. which the other end acknowledges with an ACK. Therefore, a typical tear-down requires a pair of FIN and ACK segments from each TCP endpoint. After the side that sent the first FIN has responded with the final ACK, it waits for a timeout before finally closing the connection, during which time the local port is unavailable for new connections.

HTTP报文
HTTP报文是由一行一行的简单字符串组成的,HTTP报文都是纯文本。
HTTP报文包括三个部分:起始行;头部字段;主体数据。其中头部是非常重要的部分,会单独成章。
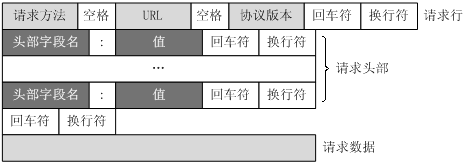 举例:
举例:
GET / HTTP/1.1
Host: www.baidu.com
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Encoding: gzip, deflate, sdch
Accept-Language: zh-CN,zh;q=0.8,en;q=0.6
Cookie: BAIDUID=4082549DEE5E64678FC46642E185D98C:FG=1
 举例:
举例:
HTTP/1.1 200 OK
Server: bfe/1.0.8.18
Date: Thu, 03 Nov 2016 08:30:43 GMT
Content-Type: text/html
Content-Length: 277
Last-Modified: Mon, 13 Jun 2016 02:50:03 GMT
Connection: Keep-Alive
ETag: "575e1f5b-115"
Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform
Pragma: no-cache
Accept-Ranges: bytes
#状态码
状态代码有三位数字组成,第一个数字定义了响应的类别,共分五种类别:
1xx:指示信息 (表示请求已接收,继续处理) 2xx:成功 (表示请求已被成功接收、理解、接受) 3xx:重定向 (要完成请求必须进行更进一步的操作) 4xx:客户端错误 (请求有语法错误或请求无法实现) 5xx:服务器端错误 (服务器未能实现合法的请求)
这里我觉得很有必要说一下的:3xx。最近开发的时候遇到一个情况:
从页面上post跳转到第三方页面,完成后对方会通过POST携带数据的方式返回到我们的页面。在前后端分离的开发模式下,暂时没有想到前端自行解决的方法,因此我们通过服务端来处理这个POST回调接受数据,再通过重定向的方式,跳回到我们自己的页面(只需要将处理结果:成功或者失败,通过url参数传给前端)。
重定向的时候,随便选择了一个307(Temporary Redirect),然后返回页面的时候还是会提示:“501 Not Implemented, 意思就是:页面不支持POST请求”。解决办法是要把这个POST转成GET咯,怎么转呢?如下:
| Code | Text | Method handling | Typical use case |
|---|---|---|---|
| 302 | Found | GET methods unchanged.Others may or may not be changed to GET | The Web page is temporarily not available for reasons that have not been unforeseen. That way, search engines don’t update their links. |
| 303 | See Other | GET methods unchanged.Others changed to GET (body lost). | Used to redirect after a PUT or a POST to prevent a refresh of the page that would re-trigger the operation. |
| 307 | Temporary | Redirect Method and body not changed. | The Web page is temporarily not available for reasons that have not been unforeseen. That way, search engines don’t update their links. Better than 302 when non-GET links/operations are available on the site. |
我们需要的就是303了:
http.Redirect(w, r, url, 303) // 把r(POST)重定向到url(GET)
HTTP头部
这部分也就是常说的Header,在HTTP协议中头部主要作用为:传递额外信息。在HTTP中头部常见分类有:请求头部/响应头部/通用头部/实体头部。 这里也不细说每个请求头的作用了(反正都是搜集别人的资料~,可以参见MDN HTTP Headers),就放几个可能会有帮助的:
#Set-Cookie [Response]
发送cookies到客户端,客户端请求的时候带上Cookie发送给服务端,可以完成一些验证。
Set-Cookie: <cookie-name>=<cookie-value>
Set-Cookie: <cookie-name>=<cookie-value>; Expires=<date>
Set-Cookie: <cookie-name>=<cookie-value>; Max-Age=<non-zero-digit>
Set-Cookie: <cookie-name>=<cookie-value>; Domain=<domain-value>
Set-Cookie: <cookie-name>=<cookie-value>; Path=<path-value>
Set-Cookie: <cookie-name>=<cookie-value>; Secure
Set-Cookie: <cookie-name>=<cookie-value>; HttpOnly
Set-Cookie: <cookie-name>=<cookie-value>; SameSite=Strict
Set-Cookie: <cookie-name>=<cookie-value>; SameSite=Lax
// Multiple directives are also possible, for example:
Set-Cookie: <cookie-name>=<cookie-value>; Domain=<domain-value>; Secure; HttpOnly
#Access-Control-Allow-Origin [Repsonse]
允许哪个域可以访问你的资源
Access-Control-Allow-Origin: *
Access-Control-Allow-Origin: <origin>
#Access-Control-Allow-Credentials [Response]
跨域请求必设置
The Access-Control-Allow-Credentials header works in conjunction with the
XMLHttpRequest.withCredentialsproperty or with thecredentialsoption in the Request() constructor of theFetch API. Credentials must be set on both sides (the Access-Control-Allow-Credentials header and in the XHR or Fetch request) in order for the CORS request with credentials to succeed.
Access-Control-Allow-Credentials: true
#Access-Control-Allow-Methods [Response]
响应头指定访问资源以响应预检请求时允许的方法。
Access-Control-Allow-Methods: <method>, <method>, ...
#Access-Control-Allow-Headers [Response]
(预检请求)用于指明在实际请求中可以使用哪些HTTP头。
Access-Control-Allow-Headers: <header-name>, <header-name>, ...
#Content-Type [Response/Request]
用于表明资源是哪种格式
Content-Type: text/html; charset=utf-8
Content-Type: multipart/form-data; boundary=something
HTTP Methods
| 方法 | 描述 | 使用场景 | 请求是否有body | 响应是否有body |
|---|---|---|---|---|
| GET | 获取指定资源 | 获取网页,查询资源 | 没有 | 有 |
| POST | 发送数据给服务端 | 新建资源;用户通过表单登录 | 有 | 有 |
| PUT | 新建资源或者替换指定资源 | 更新一条记录 | 有 | 有 |
| DELETE | 删除指定资源 | 删除一条记录; | 有 | 有 |
| OPTIONS | 用于描述特定资源的访问选项 | 获取服务端支持的请求方法 | 没有 | 有 |
| CONNECT | 开启双向通信 | undefined | 没有 | 有 |
| HEAD | 描述 | 使用场景 | 没有 | 没有 |
| PATCH | 对资源部分更改 | 使用场景 | 有 | 没有 |
| TRACE | 描述 | 使用场景 | 有 | 有 |
#GET和POST区别
被人熟知的区别有以下几点:
- GET后退按钮/刷新无害,POST数据会被重新提交(浏览器应该告知用户数据会被重新提交)。
- GET能被缓存,POST大部分不缓存。
- GET编码类型application/x-www-form-url,POST编码类型encodedapplication/x-www-form-urlencoded 或 multipart/form-data。为二进制数据使用多重编码。
- GET对数据长度有限制,当发送数据时,GET方法向URL添加数据;URL 的长度是受限制的(URL的最大长度是2048个字符。POST无限制。
- GET只允许ASCII字符。POST没有限制。也允许二进制数据。
- 与 POST 相比,GET的安全性较差,因为所发送的数据是URL的一部分。
上述是从表象来说两者有什么区别,那么从方法语义呢?HTTP协议中GET和POST的区别好吧,其实就是说:GET请求对于资源不应该产生影响,POST 请求会造成资源变化,且多次请求变化不固定(非幂等)。
#PUT和POST区别
同一个PUT调用多次,不对产生其他影响,返回结果一致,资源变化一致。但是多次提交相同的POST可能会有不一样的响应,根据设计的不同,服务端可能提示:资源重复,或者新增相同的资源多次。也就是说PUT幂等,POST非幂等。
总结
上述只能算HTTP协议的小部分知识,其包含及相关知识还有很多,如基本的HTTP鉴权,HTTPS的工作流程,HTTP如何基于TCP/IP协议来实现的。